Gemma 4 图解指南:Google DeepMind 开源模型家族全面解析
Google DeepMind 发布了 Gemma 4 系列模型,作者 Maarten Grootendorst(刚入职 Google DeepMind)以丰富的可视化方式详细拆解了这一系列模型的架构设计。
四款模型,覆盖多种场景
• Gemma 4 E2B — 密集模型,等效 20 亿参数,适合端侧部署
• Gemma 4 E4B — 密集模型,等效 40 亿参数,适合端侧部署
• Gemma 4 31B — 310 亿参数的密集模型
• Gemma 4 26B A4B — MoE 架构,总参数 260 亿,推理时仅激活 40 亿参数,兼顾性能与效率
所有模型均为多模态,支持图像输入;小模型(E2B/E4B)还额外支持音频输入。
核心架构亮点
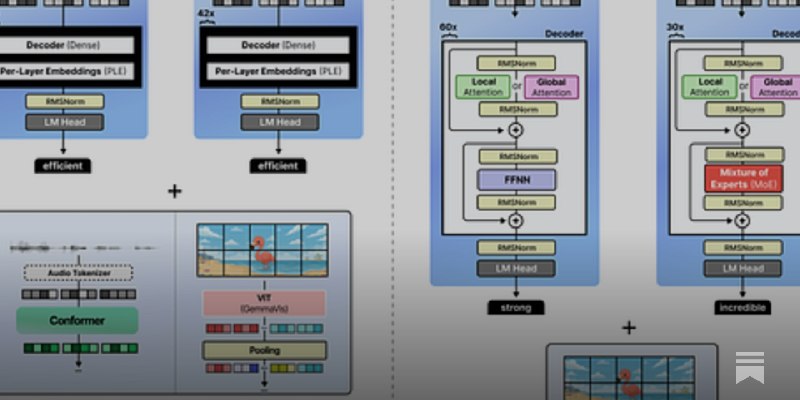
注意力机制优化:
• 局部注意力(滑动窗口)与全局注意力交替堆叠(5:1 或 4:1),最后一层始终为全局注意力
• 全局注意力层采用 8 个 Query 共享 1 个 KV 头的分组查询注意力(GQA)
• K=V 技巧:全局注意力层中 Key 等于 Value,进一步压缩 KV 缓存
• p-RoPE:仅对前 25% 维度施加旋转位置编码,避免低频维度引入噪声,提升长上下文处理能力
视觉编码器:
• 基于 Vision Transformer(ViT),支持可变宽高比和可变分辨率
• 通过 2D RoPE 编码 patch 的二维位置信息
• 引入 soft token budget(70/140/280/560/1120),用户可按任务需求灵活选择分辨率
MoE 架构(26B A4B):
• 128 个专家中每次激活 8 个 + 1 个始终激活的共享专家(3 倍大小)
• 虽然总参数 260 亿,推理速度接近 40 亿参数模型
Per-Layer Embeddings(E2B/E4B):
• 每一层都有独立的 token embedding 查找表,存储在闪存而非显存中
• 让小模型在有限 RAM 下也能获得更强的表达能力,非常适合手机等端侧设备
音频编码器(E2B/E4B):
• 基于 Conformer 架构,通过梅尔频谱图提取特征并下采样为 soft token
• 支持语音识别和翻译等任务
🔗 https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4
#Gemma4 #GoogleDeepMind #多模态 #MoE #开源模型
Google DeepMind 发布了 Gemma 4 系列模型,作者 Maarten Grootendorst(刚入职 Google DeepMind)以丰富的可视化方式详细拆解了这一系列模型的架构设计。
四款模型,覆盖多种场景
• Gemma 4 E2B — 密集模型,等效 20 亿参数,适合端侧部署
• Gemma 4 E4B — 密集模型,等效 40 亿参数,适合端侧部署
• Gemma 4 31B — 310 亿参数的密集模型
• Gemma 4 26B A4B — MoE 架构,总参数 260 亿,推理时仅激活 40 亿参数,兼顾性能与效率
所有模型均为多模态,支持图像输入;小模型(E2B/E4B)还额外支持音频输入。
核心架构亮点
注意力机制优化:
• 局部注意力(滑动窗口)与全局注意力交替堆叠(5:1 或 4:1),最后一层始终为全局注意力
• 全局注意力层采用 8 个 Query 共享 1 个 KV 头的分组查询注意力(GQA)
• K=V 技巧:全局注意力层中 Key 等于 Value,进一步压缩 KV 缓存
• p-RoPE:仅对前 25% 维度施加旋转位置编码,避免低频维度引入噪声,提升长上下文处理能力
视觉编码器:
• 基于 Vision Transformer(ViT),支持可变宽高比和可变分辨率
• 通过 2D RoPE 编码 patch 的二维位置信息
• 引入 soft token budget(70/140/280/560/1120),用户可按任务需求灵活选择分辨率
MoE 架构(26B A4B):
• 128 个专家中每次激活 8 个 + 1 个始终激活的共享专家(3 倍大小)
• 虽然总参数 260 亿,推理速度接近 40 亿参数模型
Per-Layer Embeddings(E2B/E4B):
• 每一层都有独立的 token embedding 查找表,存储在闪存而非显存中
• 让小模型在有限 RAM 下也能获得更强的表达能力,非常适合手机等端侧设备
音频编码器(E2B/E4B):
• 基于 Conformer 架构,通过梅尔频谱图提取特征并下采样为 soft token
• 支持语音识别和翻译等任务
🔗 https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4
#Gemma4 #GoogleDeepMind #多模态 #MoE #开源模型