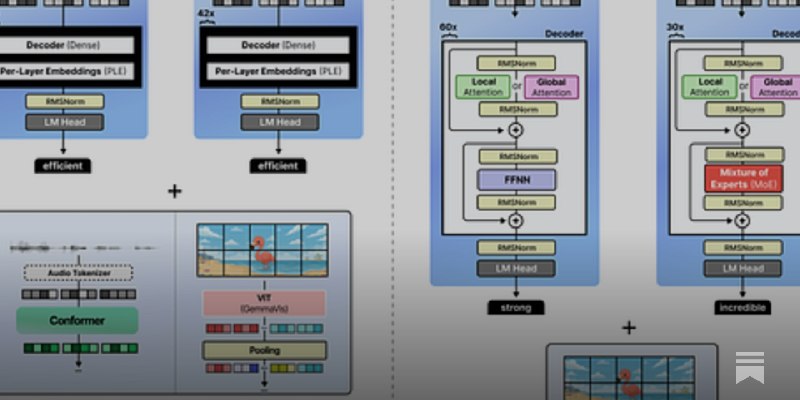
大模型省钱新招:把长文本变成“图片”传给AI,成本直接减半
我们在使用大语言模型(LLM)处理长上下文任务时,Token 费用往往会随着对话轮数呈指数级上升。虽然可以通过自动压缩或摘要来减少 Token,但这样经常会丢失关键细节,导致模型“变笨”。
开发者 Can Bölük 提出了一个脑洞大开但非常有效的解决方案:Snapcompact。
💡 核心思路:把字“画”给AI看
• 像素级压缩:将 10,000 Token 左右的长文本,用极小的像素字体(如 6x10)渲染成一张 1568x1568 的 PNG 图片。
• Token 薅羊毛:根据 Anthropic 等主流厂商的计费规则,这张图片仅折合 3,279 个图片 Token。相比直接传递文本,输入成本直降近 70%。
• 无损还原:测试表明,Claude、GPT-5.5、Gemini 等多模态模型能够近乎完美地“读懂”图中的微缩文字,答题准确率与输入原生文本几乎一致。
🔬 为什么这个方案可行?
作者使用开源多模态模型 Qwen2.5-VL-7B 进行了深度探究。通过分析模型内部的隐藏状态发现,模型在处理这类文字图时,内部的表征会迅速向文本表征靠拢。
为了防止模型“看错”,作者还做了针对性优化:
1. 对齐视觉网格:让文字排版契合模型的 Patch 切片(如 28x28 像素)。
2. 行重复与色彩辅助:通过将每行文字重复渲染,让模型读取的置信度直接从 0.39 飙升到 1.00(几乎 100% 准确)。
总结
有时候不需要改变模型本身,只需改变上下文的“载体格式”(文本 ➔ 像素图),就能在保持精度的前提下,把长文本账单砍掉一半以上。
原链接:https://blog.can.ac/2026/06/10/snapcompact/
#大语言模型 #多模态 #Token优化 #降本增效 #技术前沿
我们在使用大语言模型(LLM)处理长上下文任务时,Token 费用往往会随着对话轮数呈指数级上升。虽然可以通过自动压缩或摘要来减少 Token,但这样经常会丢失关键细节,导致模型“变笨”。
开发者 Can Bölük 提出了一个脑洞大开但非常有效的解决方案:Snapcompact。
💡 核心思路:把字“画”给AI看
• 像素级压缩:将 10,000 Token 左右的长文本,用极小的像素字体(如 6x10)渲染成一张 1568x1568 的 PNG 图片。
• Token 薅羊毛:根据 Anthropic 等主流厂商的计费规则,这张图片仅折合 3,279 个图片 Token。相比直接传递文本,输入成本直降近 70%。
• 无损还原:测试表明,Claude、GPT-5.5、Gemini 等多模态模型能够近乎完美地“读懂”图中的微缩文字,答题准确率与输入原生文本几乎一致。
🔬 为什么这个方案可行?
作者使用开源多模态模型 Qwen2.5-VL-7B 进行了深度探究。通过分析模型内部的隐藏状态发现,模型在处理这类文字图时,内部的表征会迅速向文本表征靠拢。
为了防止模型“看错”,作者还做了针对性优化:
1. 对齐视觉网格:让文字排版契合模型的 Patch 切片(如 28x28 像素)。
2. 行重复与色彩辅助:通过将每行文字重复渲染,让模型读取的置信度直接从 0.39 飙升到 1.00(几乎 100% 准确)。
总结
有时候不需要改变模型本身,只需改变上下文的“载体格式”(文本 ➔ 像素图),就能在保持精度的前提下,把长文本账单砍掉一半以上。
原链接:https://blog.can.ac/2026/06/10/snapcompact/
#大语言模型 #多模态 #Token优化 #降本增效 #技术前沿